

Hadoop thesis has its most useful application for business infrastructure; it acts as a storage platform. Hadoop thesis stores large amount of data in an effective manner by using innovative methods.
Applications of Hadoop Thesis:
- Analyze financial service in retail marketing.
- Medical health care system drug analyze.
- Data movement analyze in life science.
- Whole scale marketing.
- Social network behavior
In our concern we concentrate on hadoop thesis to achieve in high reliability and scalability service on the file storage system.
Hadoop at glance:
Apache hadoop developed by apache software foundation is an open source available project. The application areas of apache hadoop are twitter, linked in, face book, eBay. From thousands of storage server, large scale of data processing is allowed in apache hadoop. The hardware components are expensive. The failure of components in storage server system can be detected by software components in apache hadoop. Our technical team absorbs the current technologies of changes in hadoop so as to guide students and scholars.
Components of apache hadoop:
- Hadoop mapreduce framework.
- Hadoop distributed file system.
Distributed file storage process is supported by the components.
Hadoop distributed file system:
To frame a single global file system the ADFS file system group every node in a hadoop cluster; where signal file can be stored in large block. Reliable parameter can be achieved by repeating the data process among servers. Hadoop process is switched to mapreduce framework. Once the data is stored in HDFS
Map reduce
Google developed map reduce which is a programming model. Large quantity of input data is divided to multiple chunks which is supported in map reduces.
Elements of map reduce:
- Reduce()
- Scheduler()
- Map()
Along with HDFS file system, map reduce can work. Map reduce framework is laid out for batch processing of data set to derive correct result.
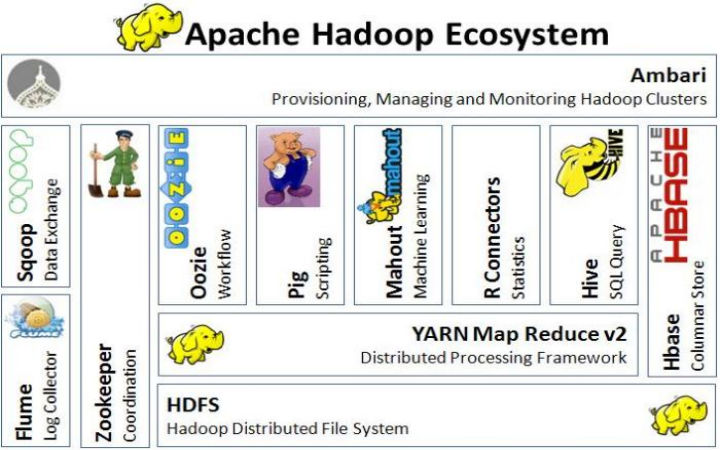
Hadoop-Project-Ecosystem
Maps reduce characteristics:
- From task pool the failure jobs can be recovered quickly.
- Failure jobs can be re-executed.
- Load balancing can be improved
- Redundancy of data can be avoided and location of input data can be maintained.
- For big data application, map reduce and ADFS system server as a well efficient solution.
Service of hadoop data:
For easy calculating and processing of data from multiple user apache hadoop use data service tool.
Apache Hbase:
- Non relational database
- Storage of large volume of data
- Fast of quick retrieval of data from data base.
Apache sqoop:
- Transferring bulk of data from apache hadoop to relational data base
- Allows extraction of data from internal HDFS system or external sources.
Apache H catalog:
- Acts as a table of storage management layer is hadoop frame work.
- Allows writing and reading operations in easy way.
- For various users allow the pig, hive and map reduce application.
Apache big:
- Defines sorting of joining of data, data aggregation.
- Permits complex map reduce transformation by pig latin known as scripting language.
Apache Hive
- For data warehouse act as an infrastructure.
- Useful for providing analysis of large database, ad-hoc query and large data summarization.
- It can merge visualization tool and hadoop application framework for various business application.
Hadoop thesis future opportunity:
Various applications of apache hadoop
- Processing
- Analyze large data volume.
The future generation work on apache Horton works data platform for their data mining research. Our firm has supported more than and has gained success.














